

Paris: Mistral AI, high-performance AI company introduced Voxtral Transcribe 2, the company’s second-generation speech-to-text models aimed at delivering faster, more accurate, and lower-cost transcription. The release includes two variants, Voxtral Mini Transcribe V2 for batch processing and Voxtral Realtime for live audio applications with latency configurable down to sub-200 milliseconds.
In a post on X, the company described it as “next-gen speech-to-text” offering state-of-the-art transcription, speaker diarization, and sub-200ms real-time latency.
The Paris-based AI firm said the new models are designed to compete directly with leading transcription services while significantly reducing costs. Voxtral Mini Transcribe V2 is priced at $0.003 per minute for batch jobs, which the company says is roughly one-fifth the cost of competing offerings such as ElevenLabs’ Scribe v2.
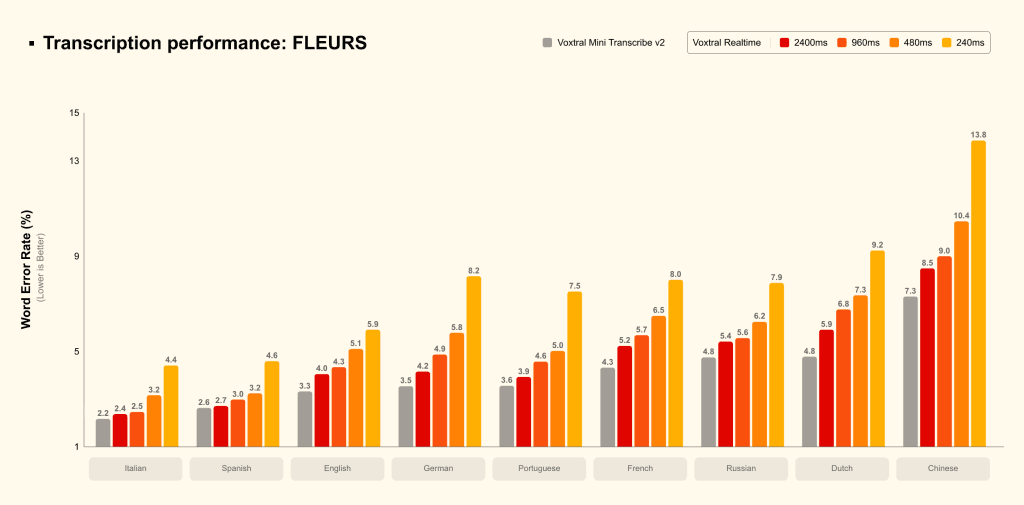
According to Mistral’s internal benchmarks, the models deliver about a 4%-word error rate on the FLEURS dataset, outperforming several well-known transcription systems while also processing audio up to three times faster than some rivals. The company added that the real-time model can match batch-level accuracy at higher latency settings suitable for live subtitling, while lower latency modes introduce only a small increase in error rates.

Voxtral Mini Transcribe V2 includes features such as speaker diarization, word-level timestamps, and context biasing that allow users to add up to 100 domain-specific terms for improved accuracy. Voxtral Realtime, meanwhile, is built for voice agents, live captioning, and call-center automation.
Notably, Voxtral Realtime is released under the Apache 2.0 license, allowing organizations to deploy it on-premises without relying on external APIs. With a 4-billion-parameter footprint capable of running on edge devices, the models are positioned for industries with strict data-privacy requirements, including healthcare and finance.


